Доверительный интервал. Доверительная вероятность. Вычисление доверительного интервала в Microsoft Excel
«Катрен-Стиль» продолжает публикацию цикла Константина Кравчика о медицинской статистике. В двух предыдущих статьях автор касался объяснения таких понятий, как и .
Константин Кравчик
Математик-аналитик. Специалист в области статистических исследований в медицине и гуманитарных науках
Город: Москва
Очень часто в статьях по клиническим исследованиям можно встретить загадочное словосочетание: «доверительный интервал» (95 % ДИ или 95 % CI - confidence interval). Например, в статье может быть написано: «Для оценки значимости различий использовали t-критерий Стьюдента с расчетом 95 % доверительного интервала».
Какого же значение «95 % доверительного интервала» и зачем его рассчитывать?
Что такое доверительный интервал? - Это диапазон, в котором находятся истинные средние значения в генеральной совокупности. А что, бывают «неистинные» средние значения? В каком‑то смысле да, бывают. В мы объясняли, что невозможно измерить интересующий параметр во всей генеральной совокупности, поэтому исследователи довольствуются ограниченной выборкой. В этой выборке (например, по массе тела) есть одно среднее значение (определенный вес), по которому мы и судим о среднем значении во всей генеральной совокупности. Однако едва ли средний вес в выборке (особенно небольшой) совпадет со средним весом в генеральной совокупности. Поэтому более правильно рассчитывать и пользоваться диапазоном средних значений генеральной совокупности.
Например, представим, что 95 % доверительный интервал (95 % ДИ) по гемоглобину составляет от 110 до 122 г/л. Это означает, что с вероятностью 95 % истинное среднее значение по гемоглобину в генеральной совокупности будет находиться в пределах от 110 до 122 г/л. Иными словами, мы не знаем средний показатель гемоглобина в генеральной совокупности, но можем с 95 %-й вероятностью указать диапазон значений для этого признака.
Доверительный интервал особенно уместен для разницы в средних значениях между группами или, как это называют, в размере эффекта.
Допустим, мы сравнивали эффективность двух препаратов железа: давно присутствующего на рынке и только что зарегистрированного. После курса терапии оценили концентрацию гемоглобина в исследуемых группах пациентов, и статистическая программа нам посчитала, что разность между средними значениями двух групп с вероятностью 95 % находится в диапазоне от 1,72 до 14,36 г/л (табл. 1).
Табл. 1. Критерий для независимых выборок
(сравниваются группы по уровню гемоглобина)
Трактовать это следует так: у части пациентов генеральной совокупности, которая принимает новый препарат, гемоглобин будет выше в среднем на 1,72–14,36 г/л, чем у тех, кто принимал уже известный препарат.
Иными словами, в генеральной совокупности разность в средних значениях по гемоглобину у групп с 95 %-й вероятностью находится в этих пределах. Судить, много это или мало, будет уже исследователь. Смысл всего этого в том, что мы работаем не с одним средним значением, а с диапазоном значений, следовательно, мы более достоверно оцениваем разницу по параметру между группами.
В статистических пакетах, на усмотрение исследователя, можно самостоятельно сужать или расширять границы доверительного интервала. Снижая вероятности доверительного интервала, мы сужаем диапазон средних. Например, при 90 % ДИ диапазон средних (или разницы средних) будет уже, чем при 95 %.
И наоборот, увеличение вероятности до 99 % расширяет диапазон значений. При сравнении групп нижняя граница ДИ может пересечь нулевую отметку. Например, если мы расширили границы доверительного интервала до 99 %, то границы интервала расположились от –1 до 16 г/л. Это означает, что в генеральной совокупности есть группы, различие средних между которыми по изучаемому признаку равняется 0 (М=0).
При помощи доверительного интервала можно проверять статистические гипотезы. Если доверительный интервал пересекает нулевое значение, то нулевая гипотеза, предполагающая, что группы не различаются по изучаемому параметру, верна. Пример описан выше, когда мы расширили границы до 99 %. Где‑то в генеральной совокупности у нас нашлись группы, которые никак не различались.
95% доверительный интервал разницы по гемоглобину, (г/л)

На рисунке в виде линии изображен 95 % доверительный интервал разницы средних значений по гемоглобину между двумя группами. Линия проходит нулевую отметку, следовательно, имеет место разница между средними значениями, равная нулю, что подтверждает нулевую гипотезу о том, что группы не различаются. Диапазон разницы между группами лежит от –2 до 5 г/л, Это означает, что гемоглобин может как снизиться на 2 г/л, так и повыситься на 5 г/л.
Доверительный интервал - очень важный показатель. Благодаря ему можно посмотреть, были ли различия в группах действительно за счет разности средних или за счет большой выборки, т. к. при большой выборке шансы найти различия больше, чем при малой.
На практике это может выглядеть так. Мы взяли выборку в 1000 человек, измерили уровень гемоглобина и обнаружили, что доверительный интервал разницы средних лежит от 1,2 до 1,5 г/л. Уровень статистической значимости при этом p
Мы видим, что концентрация гемоглобина повысилась, но практически незаметно, следовательно, статистическая значимость появилась именно за счет объема выборки.
Доверительный интервал может быть высчитан не только для средних значений, но и для пропорций (и отношений рисков). Например, нас интересует доверительный интервал пропорций пациентов, которые достигли ремиссии, принимая разработанное лекарство. Допустим, что 95 % ДИ для пропорций, т. е. для доли таких пациентов, лежит в пределах 0,60–0,80. Таким образом, мы можем сказать, что наше лекарство оказывает терапевтический эффект от 60 до 80 % случаев.
И др. Все они являются оценками своих теоретических аналогов, которые можно было бы получить, если бы в распоряжении была не выборка, а генеральная совокупность. Но увы, генеральная совокупность – это очень дорого и часто недоступно.
Понятие об интервальном оценивании
Любая выборочная оценка обладает некоторым разбросом, т.к. является случайной величиной, зависящей от значений в конкретной выборке. Стало быть, для более надежных статистических выводов следует знать не только точечную оценку, но и интервал, который с высокой вероятностью γ (гамма) накрывает оцениваемый показатель θ (тета).
Формально, это два таких значения (статистики) T 1 (X) и T 2 (X) , что T 1 < T 2 , для которых при заданном уровне вероятности γ выполняется условие:
Короче, с вероятностью γ или больше истинный показатель находится между точками T 1 (X) и T 2 (X) , которые называются нижней и верхней границей доверительного интервала .
Одним из условий построения доверительных интервалов является его максимальная узость, т.е. он должен быть насколько это возможно коротким. Желание вполне естественно, т.к. исследователь старается точнее локализовать нахождение искомого параметра.
Отсюда следует, что доверительный интервал должен накрывать максимальные вероятности распределения. а сама оценка быть в центре.
![]()
То бишь вероятность отклонения (истинного показателя от оценки) в большую сторону равна вероятности отклонения в меньшую сторону. Следует также отметить, что для несимметричных распределений интервал справа не равен интервалу слева.
По рисунку выше отчетливо видно, что чем больше доверительная вероятность, тем шире интервал – прямая зависимость.
Это была небольшая вводная часть в теорию интервального оценивания неизвестных параметров. Перейдем к нахождению доверительных границ для математического ожидания.
Доверительный интервал для математического ожидания
Если исходные данные распределены по , то и среднее будет нормальной величиной. Это следует из того правила, что линейная комбинация нормальных величин также имеет нормальное распределение. Следовательно, для расчета вероятностей мы могли бы использовать математический аппарат нормального закона распределения.
Однако для этого потребуется знать два параметра – матожидание и дисперсию, которые обычно не известны. Можно, конечно, вместо параметров использовать оценки (среднюю арифметическую и ), но тогда распределение средней будет не совсем нормальным, оно будет немного приплюснуто книзу. Этот факт ловко подметил гражданин Уильям Госсет из Ирландии, опубликовав свое открытие в мартовском выпуске журнала «Biometrica» за 1908 год. В целях конспирации Госсет подписался Стьюдентом. Так появилось t-распределение Стьюдента.
Однако нормальное распределение данных, использовавшееся К. Гауссом при анализе ошибок астрономических наблюдений, в земной жизни встречается крайне редко и установить это довольно сложно (для высокой точности необходимо порядка 2 тысяч наблюдений). Поэтому предположение о нормальности лучше всего отбросить и использовать методы, не зависящие от распределения исходных данных.
Возникает вопрос: каково же распределение средней арифметической, если оно рассчитано по данным неизвестного распределения? Ответ дает известная в теории вероятностей Центральная предельная теорема (ЦПТ). В математике существует несколько ее вариантов (на протяжении долгих лет формулировки уточнялись), но все они, грубо говоря, сводятся к утверждению, что сумма большого количества независимых случайных величин подчиняется нормальному закону распределения.
При расчете средней арифметической как раз используется сумма случайных величин. Отсюда получается, что среднее арифметическое имеет нормальное распределение, у которого матожидание – это матожидание исходных данных, а дисперсия – .
Умные люди умеют доказывать ЦПТ, но мы в этом убедимся с помощью эксперимента, проведенного в Excel. Смоделируем выборку из 50-ти равномерно распределенных случайных величин (с помощью функции Excel СЛУЧМЕЖДУ). Затем сделаем 1000 таких выборок и для каждой рассчитаем среднюю арифметическую. Посмотрим на их распределение.

Видно, что распределение средней близко к нормальному закону. Если объем выборок и их количество сделать еще больше, то сходство будет еще лучше.
Теперь, когда мы воочию убедились в справедливости ЦПТ, можно, используя , рассчитать доверительные интервалы для средней арифметической, которые с заданной вероятностью накрывают истинное среднее или математическое ожидание.
Для установления верхней и нижней границы требуется знать параметры нормального распределения. Как правило, их нет, поэтому используют оценки: среднюю арифметическую и выборочную дисперсию . Повторюсь, такой способ дает хорошее приближение только при больших выборках. Когда выборки малые, часто рекомендуют использовать распределение Стьюдента. Не верьте! Распределение Стьюдента для средней бывает только тогда, когда исходные данные имеют нормальное распределение, то есть почти никогда. Поэтому лучше сразу поставить минимальную планку по количеству необходимых данных и использовать асимптотически корректные методы. Говорят, достаточно 30 наблюдений. Берите 50 – не ошибетесь.
![]()
T 1,2 – нижняя и верхняя граница доверительного интервала
– выборочное среднее арифметическое
s 0 – среднее квадратичное отклонение по выборке (несмещенное)
n – размер выборки
γ – доверительная вероятность (обычно равна 0,9, 0,95 или 0,99)
c γ =Φ -1 ((1+γ)/2) – обратное значение функции стандартного нормального распределения. По-простому говоря, это количество стандартных ошибок от средней арифметической до нижней или верхней границы (указанным трем вероятностями соответствуют значения 1,64, 1,96 и 2,58).
Суть формулы в том, что берется среднее арифметическое и далее от нее откладывается некоторое количество (с γ ) стандартных ошибок (s 0 /√n ). Все известно, бери и считай.
До массового использования ПЭВМ для получения значений функции нормального распределения и обратной ей использовали . Их и сейчас используют, но эффективнее обратиться к готовым формулам Excel. Все элементы из формулы выше ( , и ) можно легко рассчитать в Excel. Но есть и готовая формула для расчета доверительного интервала – ДОВЕРИТ.НОРМ . Ее синтаксис следующий.
ДОВЕРИТ.НОРМ(альфа;стандартное_откл;размер)
альфа – уровень значимости или доверительный уровень, который в принятых выше обозначениях равен 1- γ, т.е. вероятность того, что математическое ожидание окажется за пределами доверительного интервала. При доверительной вероятности 0,95, альфа равно 0,05 и т.д.
стандартное_откл – среднее квадратичное отклонение выборочных данных. Стандартную ошибку рассчитывать не нужно, Excel сам разделит на корень из n.
размер – размер выборки (n).
Результат функции ДОВЕРИТ.НОРМ – это второе слагаемое из формулы расчета доверительного интервала, т.е. полуинтервал. Соответственно, нижняя и верхняя точка – это среднее ± полученное значение.
Таким образом, можно построить универсальный алгоритм расчета доверительных интервалов для средней арифметической, который не зависит от распределения исходных данных. Платой за универсальность является его асимптотичность, т.е. необходимость использования относительно больших выборок. Однако в век современных технологий собрать нужное количество данных обычно не представляет трудностей.
Проверка статистических гипотез с помощью доверительного интервала
{module 111}
Одной из главных задач, решаемых в статистике, является . Ее суть вкратце такова. Выдвигается предположение, например, что матожидание генеральной совокупности равно какому-то значению. Затем строится распределение выборочных средних, которые могут наблюдаться при данном матожидании. Далее смотрят, в каком месте этого условного распределения находится реальная средняя. Если она выходит за допустимые пределы, то появление такого среднего очень маловероятно, а при однократном повторении эксперимента почти невозможно, что противоречит выдвинутой гипотезе, которая успешно отклоняется. Если же среднее не выходит за критический уровень, то гипотеза не отклоняется (но и не доказывается!).
Так вот с помощью доверительных интервалов, в нашем случае для матожидания, также можно проверять некоторые гипотезы. Это очень просто сделать. Допустим, средняя арифметическая по некоторой выборке равна 100. Проверяется гипотеза о том, что матожидание равно, допустим, 90. То есть, если поставить вопрос примитивно, то он звучит так: может ли такое быть, чтобы при истинном значении средней равной 90, наблюдаемая средняя оказалась равна 100?
Для ответа на этот вопрос дополнительно потребуется информация о среднем квадратичном отклонении и размере выборки. Допустим среднеквадратичное отклонение равно 30, а количество наблюдений 64 (чтобы легко извлечь корень). Тогда стандартная ошибка средней равна 30/8 или 3,75. Для расчета 95% доверительного интервала потребуется отложить в обе стороны от средней по две стандартные ошибки (точнее, по 1,96). Доверительный интервал получится примерно 100±7,5 или от 92,5 до 107,5.
Далее рассуждения следующие. Если проверяемое значение попадает в доверительный интервал, то оно не противоречит гипотезе, т.к. укладывается в пределы случайных колебаний (с вероятностью 95%). Если проверяемая точка выходит за пределы доверительного интервала, то вероятность такого события очень маленькая, во всяком случае ниже допустимого уровня. Значит, гипотезу отклоняют, как противоречащую наблюдаемым данным. В нашем случае гипотеза о матожидании находится за пределами доверительного интервала (проверяемое значение 90 не входит в интервал 100±7,5), поэтому ее следует отклонить. Отвечая на примитивный вопрос выше, следует сказать: нет не может, во всяком случае такое случается крайне редко. Часто при этом указывают конкретную вероятность ошибочного отклонения гипотезы (p-level), а не заданный уровень, по которому строился доверительный интервал, но об этом в другой раз.
Как видим, построить доверительный интервал для среднего (или математического ожидания) несложно. Главное, уловить суть, а дальше дело пойдет. На практике в большинстве случаев используются 95% доверительный интервал, который имеет в ширину примерно две стандартные ошибки по обе стороны от средней.
На этом пока все. Всех благ!
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а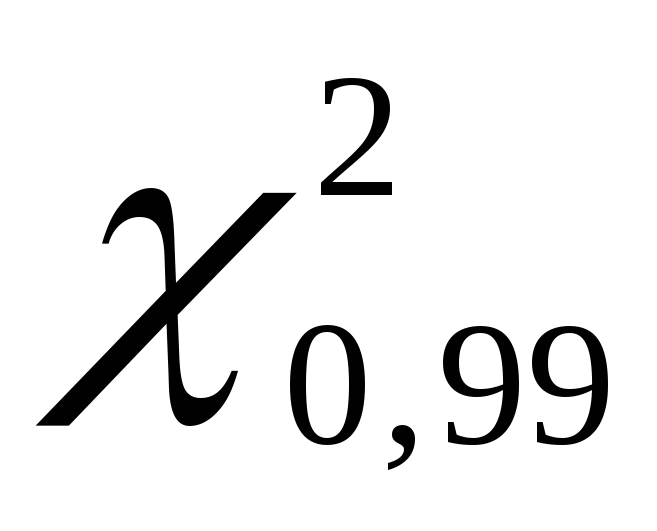 равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны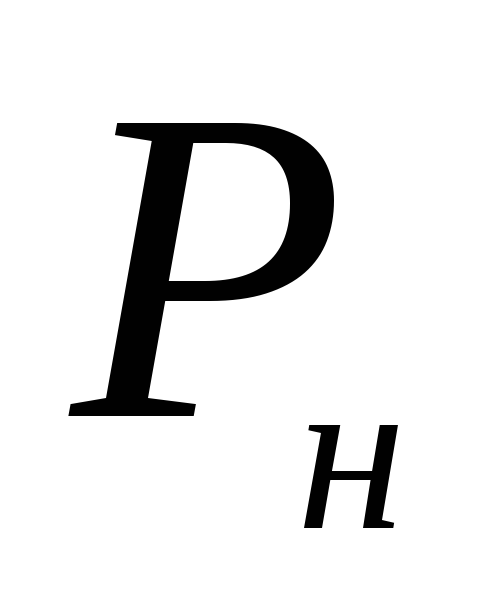 =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
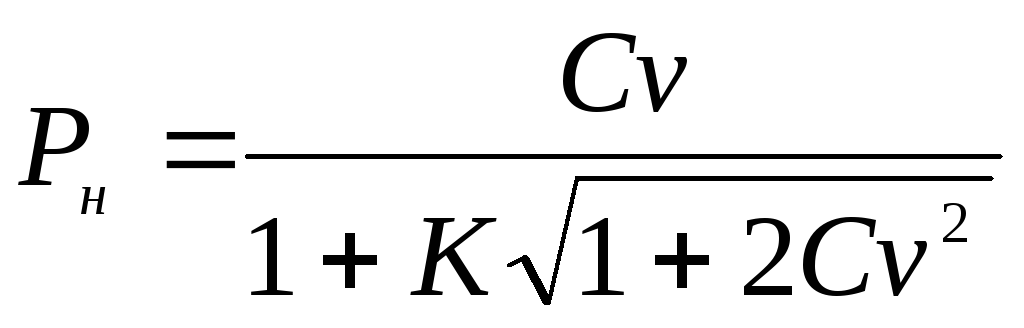 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
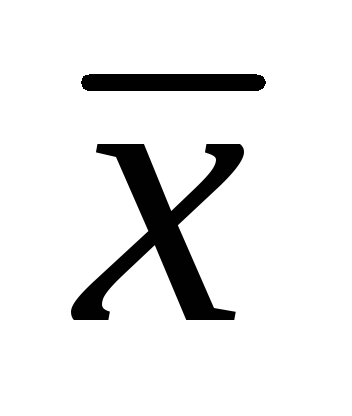 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).
Доверительный интервал (ДИ; в англ, confidence interval - CI) полученный в исследовании при выборке даёт меру точности (или неопределённости) результатов исследования, для того чтобы делать выводы о популяции всех таких пациентов (генеральная совокупность). Правильное определение 95% ДИ можно сформулировать так: 95% таких интервалов будет содержать истинную величину в популяции. Несколько менее точна такая интерпретация: ДИ - диапазон величин, в пределах которого можно на 95% быть уверенным в том, что он содержит истинную величину. При использовании ДИ акцент делается на определении количественного эффекта, в противоположность величине Р, которая получается в результате проверки статистической значимости. Величина Р не оценивает никакого количества, а служит скорее мерой силы свидетельства против нулевой гипотезы «никакого эффекта». Величина Р сама по себе не говорит нам ничего ни о величине различия, ни даже о его направлении. Поэтому самостоятельные величины Р абсолютно неинформативны в статьях или рефератах. В отличие от них ДИ указывает и на количество эффекта, представляющего непосредственный интерес, например на полезность лечения, и на силу доказательств. Поэтому ДИ непосредственно имеет отношение к практике ДМ.
Подход оценки к статистическому анализу, иллюстрируемый ДИ, направлен на измерение количества интересующего нас эффекта (чувствительность диагностического теста, частота прогнозируемых случаев, сокращение относительного риска при лечении и т.д.), а также на измерение неопределённости в этом эффекте. Чаще всего ДИ - диапазон величин по обе стороны оценки, в котором, вероятно, лежит истинная величина, и можно быть уверенным в этом на 95%. Соглашение использовать 95% вероятность произвольно, также как и величину Р <0,05 для оценки статистической значимости, и авторы иногда используют 90% или 99% ДИ. Заметим, что слово «интервал» означает диапазон величин и поэтому стоит в единственном числе. Две величины, которые ограничивают интервал, называются «доверительными пределами».
ДИ основан на идее, что то же самое исследование, выполненное на других выборках пациентов, не привело бы к идентичным результатам, но что их результаты будут распределены вокруг истинной, однако неизвестной величины. Иными словами, ДИ описывает это как «вариабельность, зависящую от выборки». ДИ не отражает дополнительную неопределённости, обусловленную другими причинами; в частности, он не включает влияние селективной потери пациентов при отслеживании, плохого комплайнса или неточного измерения исхода, отсутствия «ослепления» и т.д. ДИ, таким образом, всегда недооценивает общее количество неопределённости.
Вычисление доверительного интервала
Таблица А1.1. Стандартные ошибки и доверительные интервалы для некоторых клинических измерений
Обычно ДИ вычисляют из наблюдаемой оценки количественного показателя, такого, как различие (d) между двумя пропорциями, и стандартной ошибки (SE) в оценке этого различия. Приблизительный 95% ДИ, получаемый таким образом, - d ± 1,96 SE. Формула изменяется согласно природе меры исхода и охвату ДИ. Например, в рандомизированном плацебо-контролируемом испытании бесклеточной коклюшной вакцины коклюш развивался у 72 из 1670 (4,3%) младенцев, получивших вакцину, и у 240 из 1665 (14,4%) в группе контроля. Различие в процентах, известное как абсолютное снижение риска, составляет 10,1%. SE этого различия равна 0,99%. Соответственно 95% ДИ составляет 10,1% + 1,96 х 0,99%, т.е. от 8,2 до 12,0.
Несмотря на разные философские подходы, ДИ и тесты на статистическую значимость тесно связаны математически.
Таким образом, величина Р «значимая», т.е. Р <0,05 соответствует 95% ДИ, который исключает величину эффекта, указывающую на отсутствие различия. Например, для различия между двумя средними пропорциями это ноль, а для относительного риска или отношения шансов - единица. При некоторых обстоятельствах эти два подхода могут быть не совсем эквивалентны. Преобладающая точка зрения: оценка с помощью ДИ - предпочтительный подход к суммированию результатов исследования, но ДИ и величина Р взаимодополняющи, и во многих статьях используются оба способа представления результатов.
Неопределенность (неточность) оценки, выражаемая в ДИ, в большой степени связана с квадратным корнем из размера выборки. Маленькие выборки предоставляют меньше информации, чем большие, и ДИ соответственно шире в меньшей выборке. Например, статья, сравнивающая характеристики трёх тестов, которые применяются для диагностики инфекции Helicobacter pylori , сообщила о чувствительности дыхательной пробы с мочевиной 95,8% (95% ДИ 75-100). В то время как число 95,8% выглядит внушительно, маленькая выборка из 24 взрослых пациентов с Я. pylori означает, что имеется значительная неопределенность в этой оценке, как показывает широкий ДИ. Действительно, нижний предел 75% намного ниже, чем оценка 95,8%. Если бы такая же чувствительность наблюдалась в выборке 240 человек, то 95% ДИ составлял бы 92,5-98,0, давая больше гарантий, что тест высокочувствителен.
В рандомизированных контролируемых испытаниях (РКИ) незначимые результаты (т.е. те, где Р >0,05) особенно подвержены неверному толкованию. ДИ особенно полезен здесь, поскольку он показывает, насколько совместимы результаты с клинически полезным истинным эффектом. Например, в РКИ, сравнивающем наложение анастомоза швом и скрепками на толстой кишке , раневая инфекция развилась у 10,9% и 13,5% пациентов соответственно (Р = 0,30). 95% ДИ для этого различия составляет 2,6% (от -2 до +8). Даже в этом исследовании, включавшем 652 пациента, остаётся вероятность, что существует умеренное различие в частоте инфекций, возникающих вследствие этих двух процедур. Чем меньше исследование, тем больше неуверенность. Сунг и соавт. выполнили РКИ, чтобы сравнить инфузию октреотида со срочной склеротерапией при остром кровотечении из варикозно-расширенных вен на 100 пациентах. В группе октреотида частота остановки кровотечения составила 84%; в группе склеротерапии - 90%, что даёт Р = 0,56. Заметим, что показатели продолжающегося кровотечения аналогичны таковым при раневой инфекции в упомянутом исследовании. В этом случае, однако, 95% ДИ для различия вмешательств равен 6% (от -7 до +19). Этот интервал весьма широк по сравнению с 5% различием, которое представляло бы клинический интерес. Ясно, что исследование не исключает значительной разницы в эффективности. Поэтому заключение авторов «инфузия октреотида и склеротерапия одинаково эффективны при лечении кровотечения из варикозно-расширенных вен» определённо невалидно. В подобных случаях, когда, как здесь, 95% ДИ для абсолютного снижения риска (АСР; absolute risk reduction - ARR, англ.) включает ноль, ДИ для ЧПЛП (NNT - number needed to treat, англ.) является довольно затруднительным для толкования. ЧПЛП и его ДИ получают из величин, обратных АСР (умножая их на 100, если эти величины даны в виде процентов). Здесь мы получаем ЧПЛП = 100: 6 = 16,6 с 95% ДИ от -14,3 до 5,3. Как видно из сноски «d» в табл. А1.1, этот ДИ включает величины ЧПЛП от 5,3 до бесконечности и ЧПЛВ от 14,3 до бесконечности.
ДИ можно построить для большинства обычно употребляемых статистических оценок или сравнений. Для РКИ он включает разность между средними пропорциями, относительными рисками, отношениями шансов и ЧПЛП. Аналогично ДИ можно получить для всех главных оценок, сделанных в исследованиях точности диагностических тестов - чувствительности, специфичности, прогностической значимости положительного результата (все они являются простыми пропорциями), и отношения правдоподобия - оценок, получаемых в метаанализах и исследованиях типа сравнения с контролем. Компьютерная программа для персональных компьютеров, которая покрывает многие из этих способов использования ДИ, доступна со вторым изданием «Statistics with Confidence». Макросы для вычисления ДИ для пропорций бесплатно доступны для Excel и статистических программ SPSS и Minitab на http://www.uwcm.ac.uk/study/medicine/epidemiology_ statistics/research/statistics/proportions, htm.
Множественные оценки эффекта лечения
В то время как построение ДИ желательно для первичных результатов исследования, они не обязательны для всех результатов. ДИ касается клинически важных сравнений. Например, при сравнении двух групп правилен тот ДИ, что построен для различия между группами, как показано выше в примерах, а не ДИ, который можно построить для оценки в каждой группе. Мало того, что бесполезно давать отдельные ДИ для оценок в каждой группе, это представление может вводить в заблуждение. Точно так же правильный подход при сравнении эффективности лечения в различных подгруппах - сравнение двух (или более) подгрупп непосредственно. Неправильно предполагать, что лечение эффективно только в одной подгруппе, если ее ДИ исключает величину, соответствующую отсутствию эффекта, а другие - нет . ДИ полезны также при сравнении результатов в нескольких подгруппах. На рис. А 1.1 показан относительный риск эклампсии у женщин с преэклампсией в подгруппах женщин из плацебо-контролируемого РКИ сульфата магния.
Рис. А1.2. Лесной график показывает результаты 11 рандомизированных клинических испытаний бычьей ротавирусной вакцины для профилактики диареи в сравнении с плацебо. При оценке относительного риска диареи использован 95% доверительный интервал. Размер чёрного квадрата пропорционален объёму информации. Кроме того, показана суммарная оценка эффективности лечения и 95% доверительного интервала (обозначается ромбом). В метаанализе использована модель случайных эффектов превышает некоторые предварительно установленные; например, это может быть размер, использованный при вычислении величины выборки. В соответствии с более строгим критерием весь диапазон ДИ должен показывать пользу, превышающую предустановленный минимум.
Мы уже обсуждали ошибку, когда отсутствие статистической значимости принимают как указание на то, что два способа лечения одинаково эффективны. Столь же важно не уравнивать статистическую значимость с клинической важностью. Клиническую важность можно предполагать, когда результат статистически значим и величина оценки эффективности лечения
Исследования могут показать, значимы ли результаты статистически и какие из них клинически важны, а какие - нет. На рис. А1.2 приведены результаты четырёх испытаний, для которых весь ДИ <1, т.е. их результаты статистически значимы при Р <0,05 , . После высказанного предположения о том, что клинически важным различием было бы сокращение риска диареи на 20% (ОР = 0,8), все эти испытания показали клинически значимую оценку сокращения риска, и лишь в исследовании Treanor весь 95% ДИ меньше этой величины. Два других РКИ показали клинически важные результаты, которые не были статистически значимыми. Обратите внимание, что в трёх испытаниях точечные оценки эффективности лечения были почти идентичны, но ширина ДИ различалась (отражает размер выборки). Таким образом, по отдельности доказательная сила этих РКИ различна.
В статистике существует два вида оценок: точечные и интервальные. Точечная оценка представляет собой отдельную выборочную статистику, которая используется для оценки параметра генеральной совокупности. Например, выборочное среднее - это точечная оценка математического ожидания генеральной совокупности, а выборочная дисперсия S 2 - точечная оценка дисперсии генеральной совокупности σ 2 . было показано, что выборочное среднее является несмещенной оценкой математического ожидания генеральной совокупности. Выборочное среднее называется несмещенным, поскольку среднее значение всех выборочных средних (при одном и том же объеме выборки n ) равно математическому ожиданию генеральной совокупности.
Для того чтобы выборочная дисперсия S 2 стала несмещенной оценкой дисперсии генеральной совокупности σ 2 , знаменатель выборочной дисперсии следует положить равным n – 1 , а не n . Иначе говоря, дисперсия генеральной совокупности является средним значением всевозможных выборочных дисперсий.
При оценке параметров генеральной совокупности следует иметь в виду, что выборочные статистики, такие как , зависят от конкретных выборок. Чтобы учесть этот факт, для получения интервальной оценки математического ожидания генеральной совокупности анализируют распределение выборочных средних (подробнее см. ). Построенный интервал характеризуется определенным доверительным уровнем, который представляет собой вероятность того, что истинный параметр генеральной совокупности оценен правильно. Аналогичные доверительные интервалы можно применять для оценки доли признака р и основной распределенной массы генеральной совокупности.
Скачать заметку в формате или , примеры в формате
Построение доверительного интервала для математического ожидания генеральной совокупности при известном стандартном отклонении
Построение доверительного интервала для доли признака в генеральной совокупности
В этом разделе понятие доверительного интервала распространяется на категорийные данные. Это позволяет оценить долю признака в генеральной совокупности р с помощью выборочной доли р S = Х/ n . Как указывалось , если величины n р и n (1 – р) превышают число 5, биномиальное распределение можно аппроксимировать нормальным. Следовательно, для оценки доли признака в генеральной совокупности р можно построить интервал, доверительный уровень которого равен (1 – α)х100% .

где p S - выборочная доля признака, равная Х/ n , т.е. количеству успехов, деленному на объем выборки, р - доля признака в генеральной совокупности, Z - критическое значение стандартизованного нормального распределения, n - объем выборки.
Пример 3. Предположим, что из информационной системы извлечена выборка, состоящая из 100 накладных, заполненных в течение последнего месяца. Допустим, что 10 из этих накладных составлены с ошибками. Таким образом, р = 10/100 = 0,1. Доверительному уровню 95% соответствует критическое значение Z = 1,96.
Таким образом, вероятность того, что от 4,12% до 15,88% накладных содержат ошибки, равна 95%.
Для заданного объема выборки доверительный интервал, содержащий долю признака в генеральной совокупности, кажется более широким, чем для непрерывной случайной величины. Это объясняется тем, что измерения непрерывной случайной величины содержат больше информации, чем измерения категорийных данных. Иначе говоря, категорийные данные, принимающие лишь два значения, содержат недостаточно информации для оценки параметров их распределения.
В ычисление оценок, извлеченных из конечной генеральной совокупности
Оценка математического ожидания. Поправочный коэффициент для конечной генеральной совокупности (fpc ) использовался для уменьшения стандартной ошибки в раз. При вычислении доверительных интервалов для оценок параметров генеральной совокупности поправочный коэффициент применяется в ситуациях, когда выборки извлекаются без возвращения. Таким образом, доверительный интервал для математического ожидания, имеющий доверительный уровень, равный (1 – α)х100% , вычисляется по формуле:

Пример 4. Чтобы проиллюстрировать применение поправочного коэффициента для конечной генеральной совокупности, вернемся к задаче о вычислении доверительного интервала для средней суммы накладных, рассмотренной выше в примере 3. Предположим, что за месяц в компании выписываются 5000 накладных, причем X̅ =110,27долл., S = 28,95 долл., N = 5000, n = 100, α = 0,05, t 99 = 1,9842. По формуле (6) получаем:
Оценка доли признака. При выборе без возвращения доверительный интервал для доли признака, имеющий доверительный уровень, равный (1 – α)х100% , вычисляется по формуле:

Доверительные интервалы и этические проблемы
При выборочном исследовании генеральной совокупности и формулировании статистических выводов часто возникают этические проблемы. Основная из них - как согласуются доверительные интервалы и точечные оценки выборочных статистик. Публикация точечных оценок без указания соответствующих доверительных интервалов (как правило, имеющих 95%-ный доверительный уровень) и объема выборки, на основе которых они получены, может породить недоразумения. Это может создать у пользователя впечатление, что точечная оценка - именно то, что ему необходимо, чтобы предсказать свойства всей генеральной совокупности. Таким образом, необходимо понимать, что в любых исследованиях во главу угла должны быть поставлены не точечные, а интервальные оценки. Кроме того, особое внимание следует уделять правильному выбору объемов выборки.
Чаще всего объектами статистических манипуляций становятся результаты социологических опросов населения по тем или иным политическим проблемам. При этом результаты опроса выносят на первые страницы газет, а ошибку выборочного исследования и методологию статистического анализа печатают где-нибудь в середине. Чтобы доказать обоснованность полученных точечных оценок, необходимо указывать объем выборки, на основе которой они получены, границы доверительного интервала и его уровень значимости.
Следующая заметка
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 448–462
Центральная предельная теорема утверждает, что при достаточно большом объеме выборок выборочное распределение средних можно аппроксимировать нормальным распределением. Это свойство не зависит от вида распределения генеральной совокупности.